
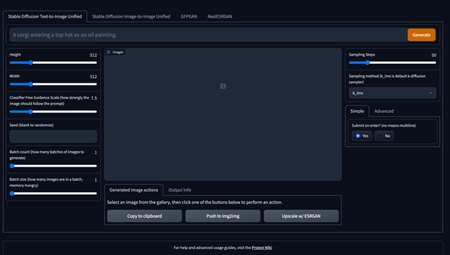
- 软件介绍
- 软件信息
- 软件截图
- 相关下载
- 下载地址
Stable Diffusion是由CompVis、Stability AI和LAION联合开发的开源文本到图像生成模型,2022年8月首次发布。基于扩散模型技术,通过逐步去除噪声生成图像,支持高分辨率输出和多平台部署,可在消费级GPU运行。其核心组件包括CLIP文本编码器、U-Net和VAE,提供文生图、图生图、图像修复等功能,适用于艺术创作、设计及跨模态生成。社区生态丰富,拥有Web UI、ComfyUI等界面工具及中文模型,支持参数调整与插件扩展,兼具高质量输出与灵活性。
Stable Diffusion功能:
1、文生图与图生图
输入文字或上传图片生成图像,支持风格转换、细节调整,可修复低质量图片并精准修改局部元素。
2、多模态创作
结合ControlNet插件实现构图控制,支持视频生成(Stable Video Diffusion)及AI模特、虚拟角色设计。
3、模型微调与扩展
通过LoRA训练专属画风模型,自定义参数控制生成效果,适配电商、影视等商业场景。
4、高效渲染优化
支持批量生成与高清修复(HiRes Fix),结合xformers等技术提升渲染速度,降低硬件压力。
Stable Diffusion特点:
1、开源免费与本地化
代码及模型开源,支持离线运行,保护用户隐私且无平台限制。
2、高质量与多样性
生成高分辨率图像,涵盖写实、动漫、油画等风格,细节丰富且色彩对比度优化。
3、灵活可控
通过提示词权重、负面词排除、种子值固定等参数精准调控生成结果,适配创意与商业需求。
4、社区生态丰富
开发者提供海量预训练模型、插件及教程,用户可共享资源并参与技术迭代。
Stable Diffusion使用方法:
1、下载并解压Stable Diffusion整合包,运行A启动器完成环境初始化,浏览器自动打开Web界面。
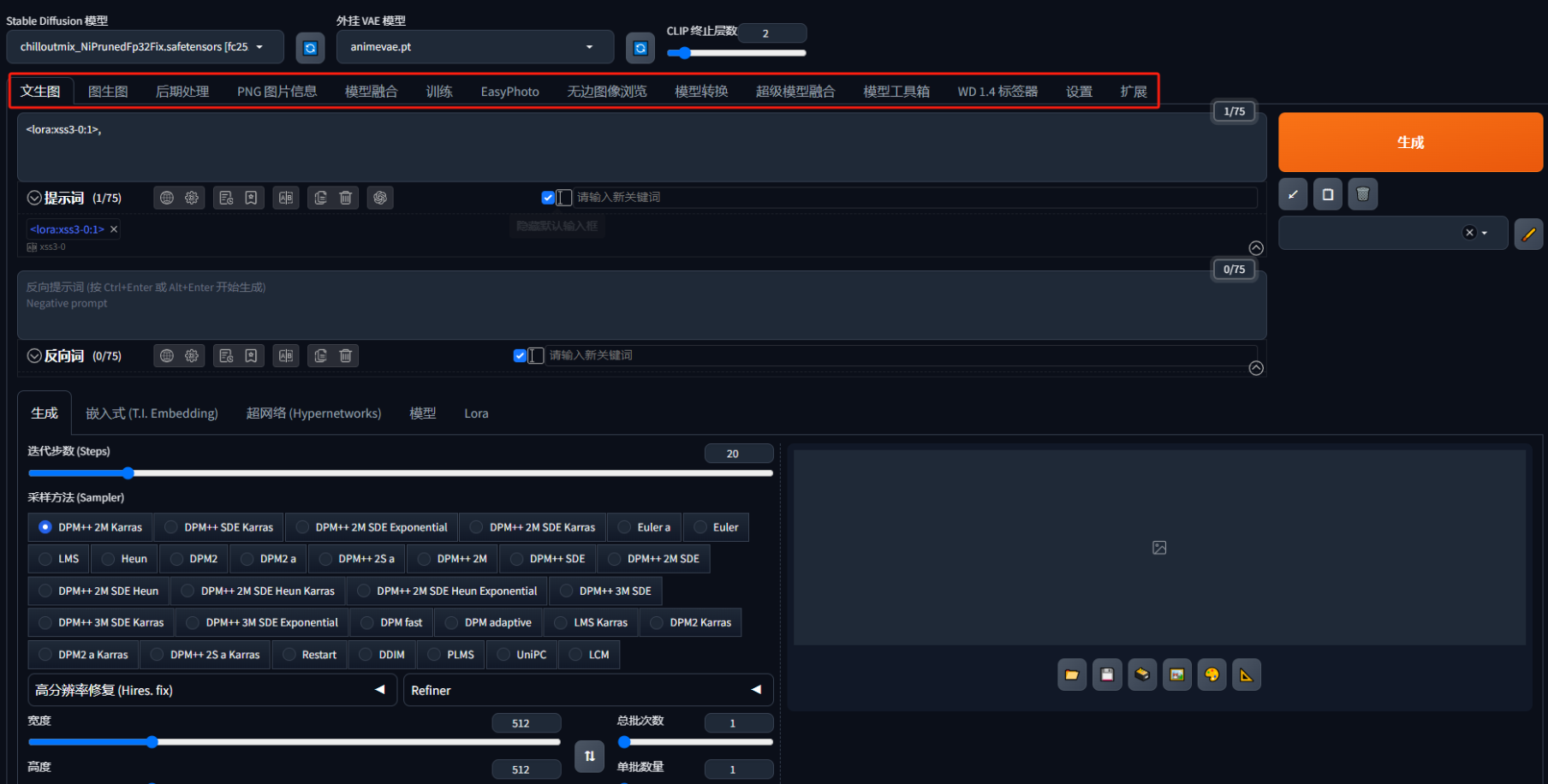
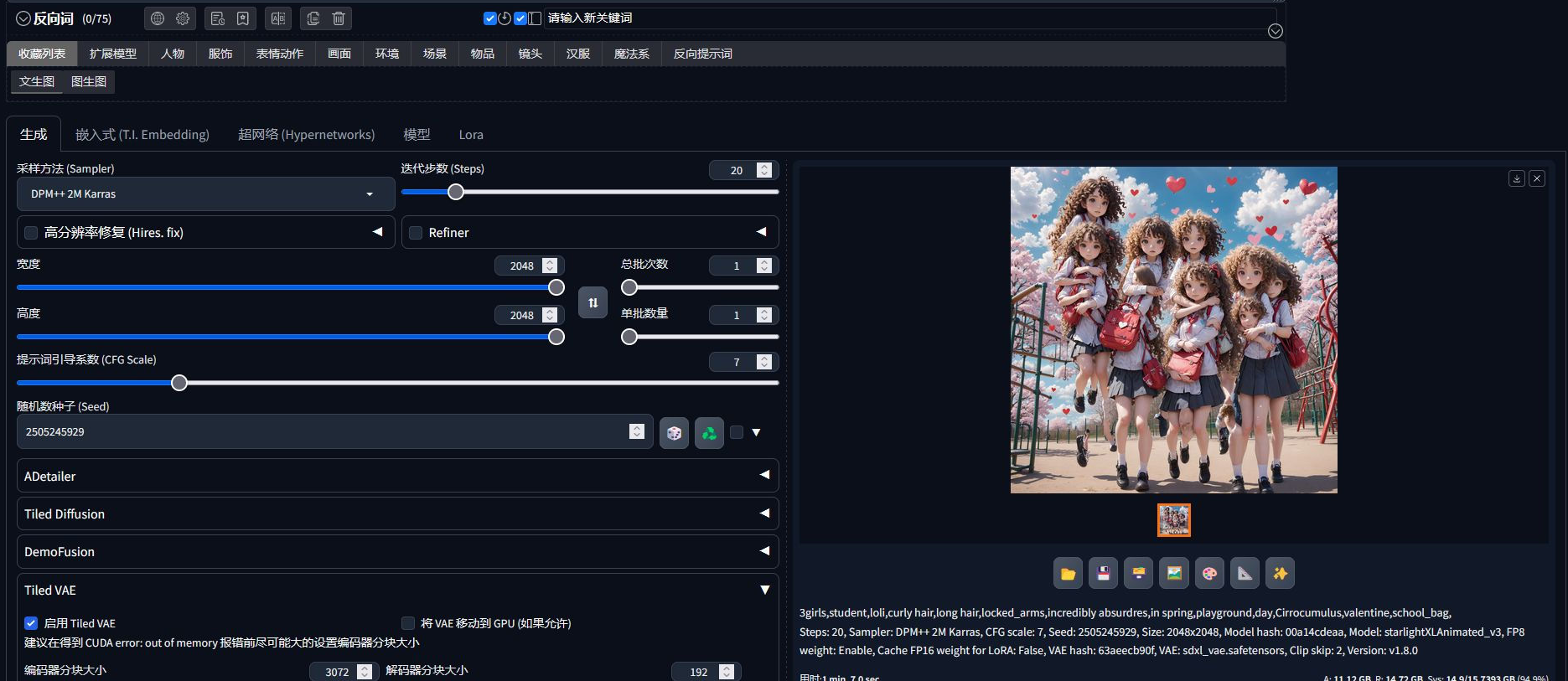
2、在文生图或图生图选项卡中输入正向/反向提示词,调整参数后点击生成。

3、结合ControlNet插件上传参考图,或通过LoRA模型调整风格,优化生成效果。
软件信息
下载地址
软件截图
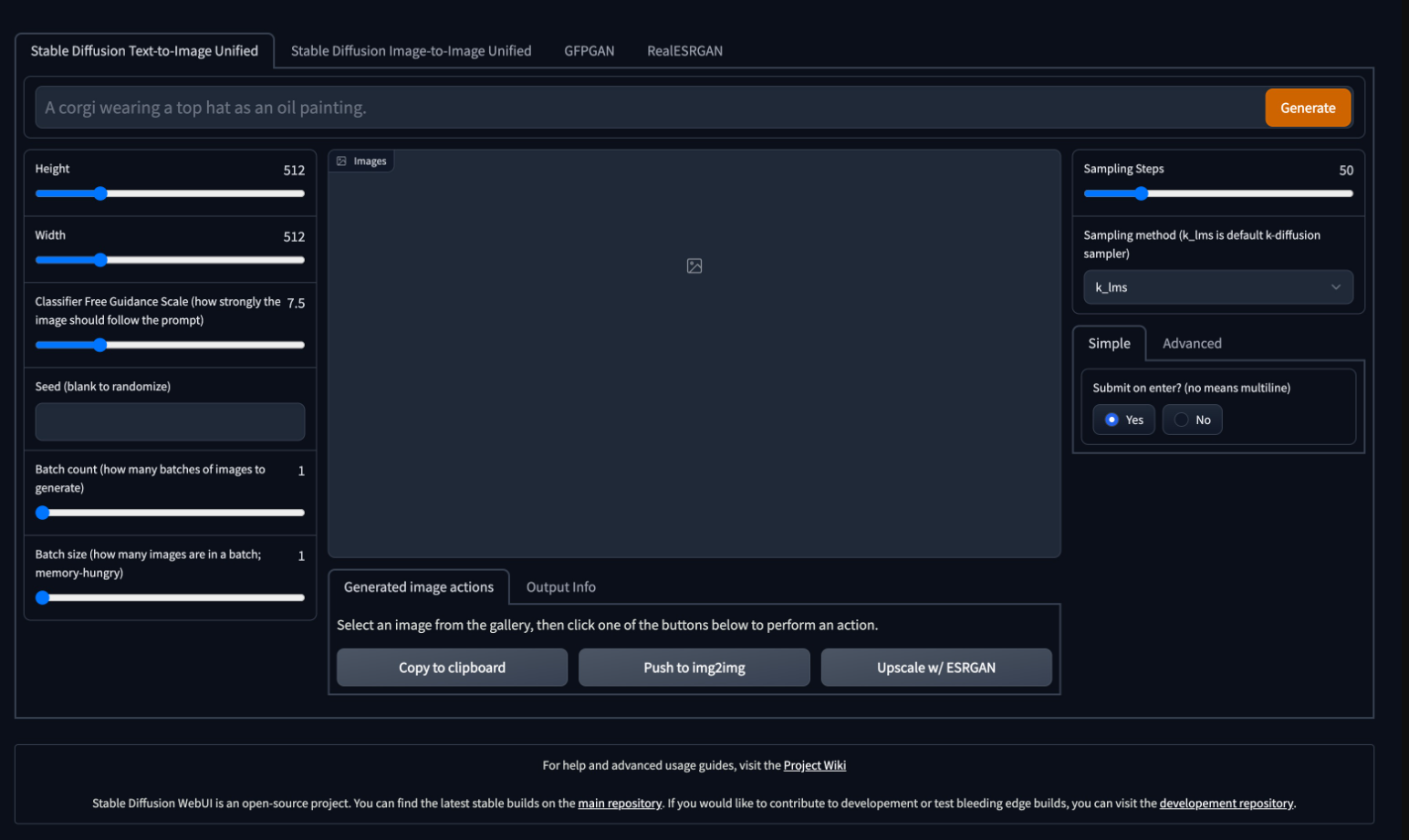
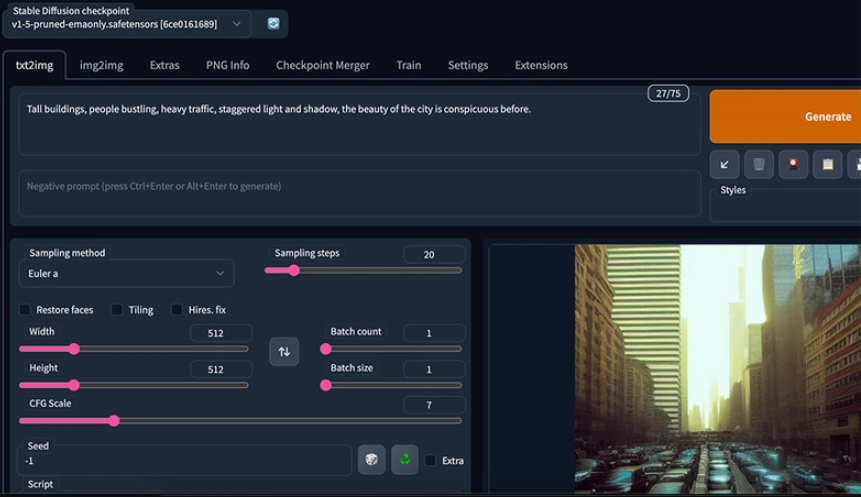
相关下载
相关推荐
-
![Kindle Comic Creator]() Kindle Comic Creator查看
Kindle Comic Creator查看39.2MB
-
![Adobe bridge免安装版]() Adobe bridge免安装版查看
Adobe bridge免安装版查看25.09MB
-
![panoramastudio pro]() panoramastudio pro查看
panoramastudio pro查看38.9MB
-
![快捷CAD]() 快捷CAD查看
快捷CAD查看6.62MB
-
![Adobe bridge中文版]() Adobe bridge中文版查看
Adobe bridge中文版查看25.09MB
-
![鸿鹄CAD永久免费版]() 鸿鹄CAD永久免费版查看
鸿鹄CAD永久免费版查看32.2MB
-
![鸿鹄CAD]() 鸿鹄CAD查看
鸿鹄CAD查看32.2MB
-
![Adobe bridge免费版]() Adobe bridge免费版查看
Adobe bridge免费版查看25.09MB
-
![artweaver plus]() artweaver plus查看
artweaver plus查看17.1MB

















































