- 软件介绍
- 软件信息
- 软件截图
- 相关下载
- 下载地址
Ultimate Vocal Remover是一款用于高质量的人声与伴奏分离的音频处理工具,它采用先进的深度学习算法,能够精准分离音频中的人声和伴奏部分,广泛应用于音乐创作、K歌伴奏制作、音频修复等领域。
Ultimate Vocal Remover软件功能
1、人声与伴奏分离
自动识别并分离音频中的人声和伴奏,提供干净的伴奏轨道。
2、多种分离模式
支持多种分离模式,如VR Architecture、MDX-Net、Demucs等,每种模式适用于不同场景。
3、易于操作
界面友好,操作简便,适合各级别用户,无需深厚的专业知识即可上手。
4、硬件加速
支持CUDA加速,可利用Nvidia GPU提高处理速度。
5、模型下载中心
内置模型下载中心,用户可根据需要下载不同模型以优化分离效果。
6、多种音频格式支持
支持MP3、WAV、FLAC等多种音频格式,输出格式包括wav、flac和mp3。
Ultimate Vocal Remover软件特色
1、先进架构
采用先进的AI模型,实现高质量的人声分离。
2、系统兼容
支持Windows、MacOS和Linux系统。
3、简化流程
界面简洁,操作简单,用户可快速上手。
4、微调分离
提供多种参数调整选项,如窗口大小、片段大小、重叠和侵略级别等。
5、组合模型
支持多种模型组合,用户可根据需求选择最佳分离方案。
Ultimate Vocal Remover安装步骤
1、在本站下载Ultimate Vocal Remover安装包。

2、双击安装包,按照提示完成安装过程。
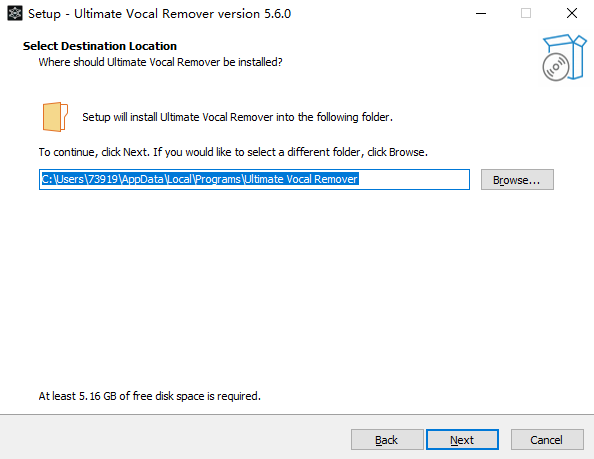
3、安装完成后,启动Ultimate Vocal Remover,即可开始使用。
软件信息
下载地址
软件截图



相关下载
相关推荐
-
![audition简化版]() audition简化版查看
audition简化版查看927MB
-
![SAM机架精编版]() SAM机架精编版查看
SAM机架精编版查看51.85MB
-
![ez cd audio converter中文版]() ez cd audio converter中文版查看
ez cd audio converter中文版查看44.4MB
-
![ACE Studio 2.0.3]() ACE Studio 2.0.3查看
ACE Studio 2.0.3查看1.11GB
-
![FxSound汉化版]() FxSound汉化版查看
FxSound汉化版查看69.19 MB
-
![FxSound]() FxSound查看
FxSound查看69.19 MB
-
![创媒DVD解码器]() 创媒DVD解码器查看
创媒DVD解码器查看4.82MB
-
![大饼AI变声器]() 大饼AI变声器查看
大饼AI变声器查看138.70MB
-
![变声器电脑版]() 变声器电脑版查看
变声器电脑版查看1.84MB